Authors: Zac Pollack, Bob Gramling
Posted: October 2024
Intro
More than 1 billion physician office visits happen every year in the United States 1 and almost none of them are currently audio recorded. This is about to change, and to change very quickly.
Driven primarily by the new capacity of artificial intelligence (AI) to automatically document clinical encounters in real time (thus offloading this increasingly burdensome task from clinicians), we are amid a re-engineering of healthcare data systems to routinely record massive amounts of conversations audio.2 On the one hand, a new conversation AI infrastructure allows nearly limitless scientific, education, and quality improvement re-imagining to empirically inform our understanding about the diversity of ways in which clinicians, patients and families communicate with one another and how best to nurture healthcare environments in support of these conversations.3 On the other hand, most AI is quite demanding on processors, particularly for large samples of time-series data such as conversations.4 Powering and cooling the machines necessary to analyze 1 billion office visits will consume a staggering amount of energy (a single data center uses the same electricity as 50,000 houses and the Cloud has surpassed the carbon impact of the global airline industry5).
Here, we explore methods of intra-conversational sampling for the purpose of saving precious computational time and energy necessary to analyze large samples of healthcare conversation audio data. Similar to how ecologists use water samples (as opposed to the whole lake) to estimate water quality and predict hazardous algae blooms, we consider the conversational pause as a promising and information dense moment to sample. Our previous work found that short audio clips of conversation surrounding longer-than-usual conversational pauses was sufficient to identify some sub-types of pauses (i.e., Connectional Silence) 6 that are epidemiologically important markers of patient-centered outcomes.7 However, as we begin to explore more fully the epidemiology and taxonomy of conversational pauses, we find ourselves asking the question:
How much data around a longer-than-usual pause do we need to analyze for the purposes of characterizing likely communicative function, meaning or clinically relevant sub-type of that pause?
What we did
We examined audio recordings of dyadic storytelling conversations from among the more than 350,000 publicly available conversations in the searchable Story Corps 8 archive. We selected 55 conversations iteratively with the goal of including a diversity of conversational topics, speaker dialects (among English language conversations) and participant identities. We sampled conversations from the general archive that typically included people who already knew one another (n=25) and from the One Small Step initiative (n=30) that included people from differing political backgrounds who did not know each other prior to the recorded conversation.
Using Whisper automated transcription and speaker diarization, we identified all pauses between speaker turns lasting at least two seconds to correspond with standard thresholds for longer-than-usual pauses.9 We identified 1,216 pauses and analyzed each using both human coding and natural language processing (NLP) methods.
Human Coding: Using 30 seconds of conversation before and 30 seconds after the start of a pause, we evaluated two potential communicative functions of each pause on 10-point ordinal scales. The first was the degree to which the pause marked a shift in speaker dynamics, such as which speaker did the most talking, tone or rate of speech and turns. The second was a change in topic or events, such as the place (e.g. workplace or home), time in one’s life (e.g. childhood or late adulthood) or the happiness/sadness of those events.
NLP: We measured three features of speech surrounding each pause. Two of these focused on prosody and one on lexicon. For prosody, we measured fundamental frequency, or f0, using Librosa’s PYIN algorithm, and speech rate using Whisper Timestamped to estimate word-per-minute. For lexicon, we used NLTK’s VADER module to measure sentiment, or the degree to which a word is typically considered “happy” or “sad” by crowdsourced evaluation.
Qualitative evaluation: We plotted each of the three NLP features for each pause with varying amounts of conversation context (audio time) surrounding the pause. We used a “short” clip of 10 seconds and medium clip of 30 seconds and “long” clip of 60 seconds. We visually inspected each plot to evaluate whether the visual patterns of the pause and varied context clips tended to convey an intuitive “shift” in feature expression.
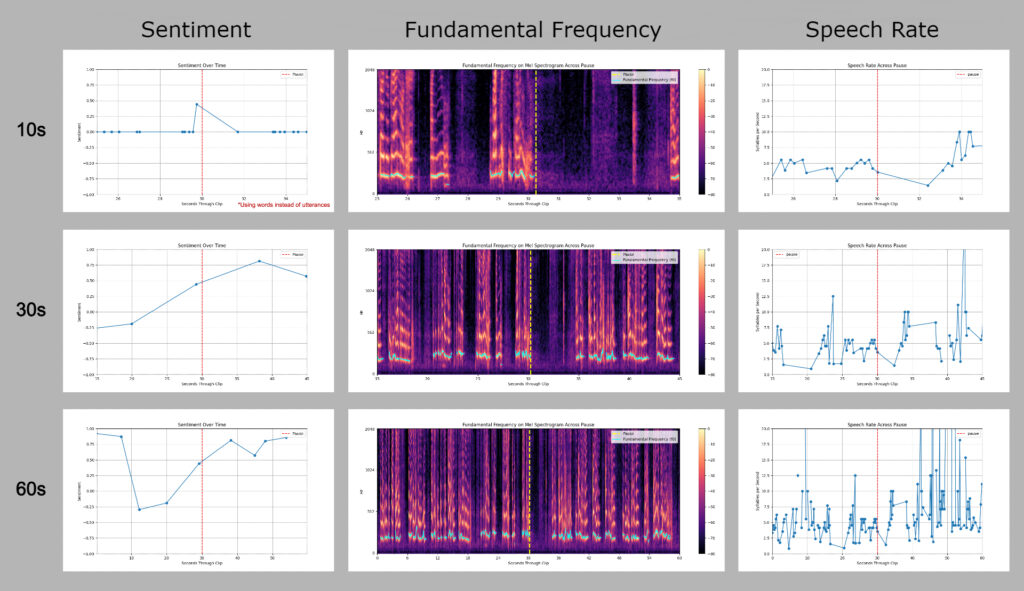
What we found
The Figure above shows the NLP feature patterns for three pauses from different conversations representing pre-post shifts in topic or speaker dynamics. For each, we display the short, medium and long contextual samples of surrounding conversation. We chose these examples to illustrate a few of our key findings.
Our main finding was that the ideal amount of conversation context to sample around each pause was different for prosody and lexical features. For prosody, we observed that fundamental frequency and speech rate required only short amounts of conversation context around the pause to demonstrate visibly intuitive pre-post changes (Fundamental Frequency 10s & Speech Rate 10s). The more distally that we sampled from the pause, the more we found that conversation “noise” tended to hide these pause-related patterns. In contrast, lexical phenomena tended to require a medium amount of context to capture the initial trajectory pattern of sentiment following the pause. (Sentiment 30s) Similar to prosody, longer amounts of conversation tended also to hide sentiment shift patterns pre-post pause.
We also observed that the ideal conversation context to sample around the pause might not be symmetric for both prosody and lexicon. Instead, we often found that the threshold for identifying patterns was more evident in the post-pause period and that the amount of information required after the pause tended to be a little longer than the information before the pause. For example, in Sentiment 30s we can see the rising trajectory in Average sentiment after the pause more clearly than shorter amounts of post-pause context (Sentiment 10s). However, the trajectory before the pause requires only a short amount of information to reveal sufficiently.
Whats next?
Our findings suggest that small-to-modest size (and potentially asymmetric) samples of conversation may be sufficient to reliably characterize the function and “types” of pauses in conversations. If so, this offers great promise for valid and efficient analysis of large scale conversation data. Our methods of selecting conversations, features to analyze, and pauses to illustrate reflect our qualitative judgements in this first phase exploratory analysis. Next steps will require specific conversation selection criteria, broader array of NLP prosody and lexical features, and more rigorous qualitative and epidemiological analyses in order to define useful benchmarks for “hot spot” sampling of conversational pauses.
References
1. Ambulatory Care Use and Physician Office Visits. Center for Disease Control & Prevention Fast Facts. 2024
(https://www.cdc.gov/nchs/fastats/physician-visits)
2. Barr P, Gramling R, Vosoughi S. Preparing for the widespread adoption of clinic visit recording. New England Journal of Medicine Artificial
Intelligence. 2024 (in press)
3. Durieux BN, Gramling R, Sanders JJ. Reprogramming Healthcare: Leveraging AI to Strengthen Doctor-Patient Relationships. Journal of
General Internal Medicine. 2024 (in press)
4. Javed A, Rizzo DM, Suk Lee B, Gramling R. SOMTimeS: Self Organizing Maps for Time Series Clustering and its Application to Serious
Illness Conversations. Data Mining & Knowledge Discovery. 2024. 38(3):813-839.
5. The Staggering Ecological Impacts of Computation and the Cloud. The MIT Press Reader. 2022 (https://thereader.mitpress.mit.edu/the-
staggering-ecological-impacts-of-computation-and-the-cloud/)
6. Matt JE, Rizzo DM, Javed A, Eppstein MJ, Gramling CJ, Manukyan V, Dewoolkar A, Gramling R. An Acoustical and Lexical Machine
Learning Ensemble to Detect Connectional Silence. Journal of Palliative Medicine. 2023. Dec;26(12):1627-1633.
7. Gramling CJ, Durieux BN, Clarfeld LA, Javed A, Matt JE, Manukyan V, Braddish T, Wong A, Wills J, Hirsch L, Straton J, Cheney N,
Eppstein MJ, Rizzo DM, Gramling R. Epidemiology of Connectional Silence in Specialist Serious Illness Conversations. Patient Education &
Counseling. 2022. Jul;105(7):2005-2011.
8. https://storycorps.org/
9. Stivers T, Enfield NJ, Brown P, Englert C, Hayashi M, Heinemann T, Hoymann G, Rossano F, de Ruiter JP, Yoon KE, Levinson SC. Universals
and cultural variation in turn-taking in conversation. Proc Natl Acad Sci U S A. 2009 Jun 30;106(26):10587-92.